I keep reading about Amazon S3 buckets in cloud storage guides, but I’m still confused about what exactly they are and how people use them. I’m trying to set up a new project and I think I need one, but I don’t know where to start. Can someone break it down in simple terms for me?
So, What Exactly Is an Amazon S3 Bucket?
Ever tried to stash your photos, documents, or even that failed meme archive somewhere safe online? That’s basically where an Amazon S3 bucket comes in—think about it like a big, digital box you get from Amazon Web Services (AWS), only instead of filling it with random stuff from your garage, you’re piling in files, images, videos, app backups, and whatever digital loot you want to keep secure (or share).
The S3 Bucket: Your Virtual Attic (No Spiders)
Okay—I’ll keep it straightforward. An Amazon S3 bucket is a container built for storing all kinds of files in the cloud. It’s part of the broader amazon s3 system, which lives inside the gigantic world of Amazon Web Services.
Unlike tossing your files on a hard drive, S3 uses something called object storage. In nerd-speak, that just means every file (aka “object”) gets its own little info card (“metadata”)—so you can easily find, share, or manage it later. And because AWS isn’t going to run off with your pictures from middle school, it’s super reliable, too.
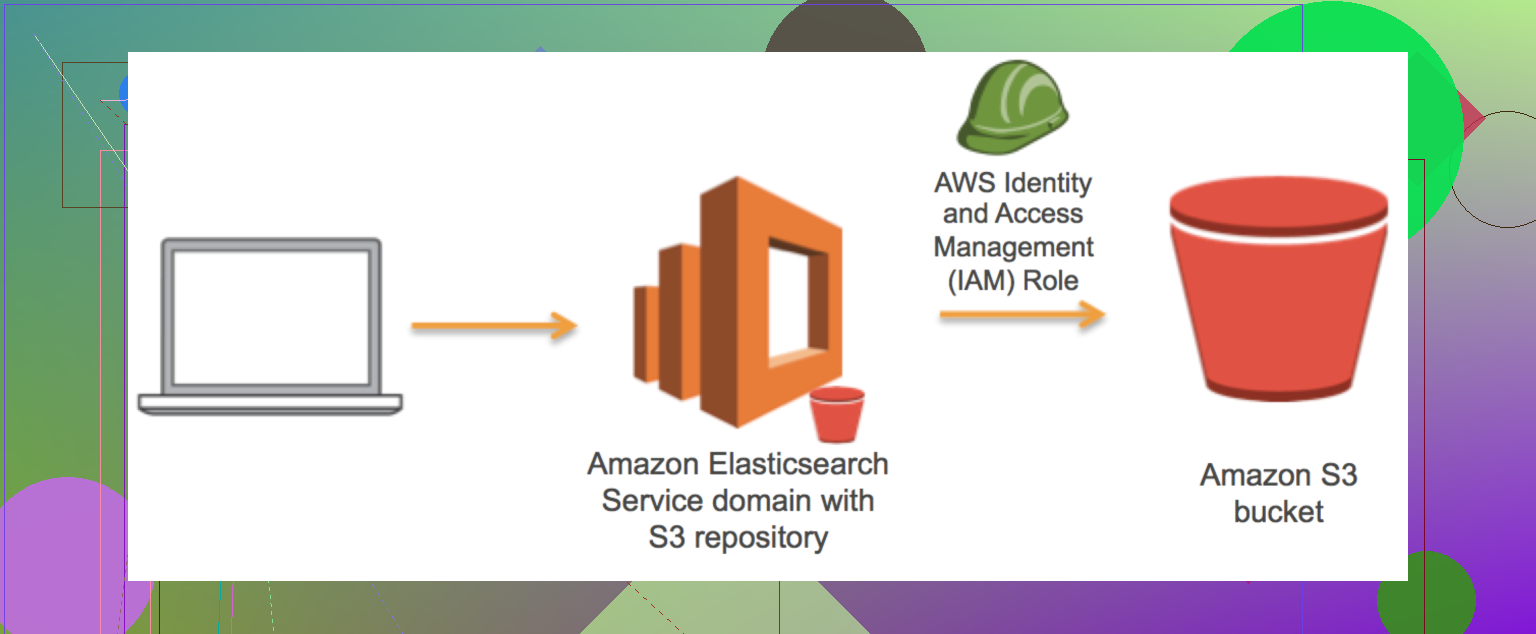
Trying to Copy S3 Stuff Between AWS Accounts? Here’s a Shortcut
If you’re losing sleep over how to move a bucket full of data from one AWS account to another (imagine passing a suitcase through airport security—sometimes it’s easy, sometimes it gets complicated), you’ll want to check this out: copy s3 bucket between accounts. Jump into the thread for real-user hacks, gotchas, and honestly, some workarounds that Amazon’s own docs leave out.
Need-to-Know Summary
- Amazon S3 bucket = limitless online storage container for your files, thanks to AWS.
- It’s all object storage, so you’ll never lose something because you forgot what folder it lived in.
- There’s a whole universe of AWS power users who have tangled with S3 data copying—seriously, don’t miss their advice.
Here’s what it looks like on the inside (minus the dust bunnies):
18 Likes
Here’s the thing: an S3 bucket is pretty much the digital version of a bottomless tote bag—except way less stylish and full of objects rather than gum wrappers. You might see people making it all fancy and complex (shout out to @mikeappsreviewer for the attic analogy), but the bucket itself? It’s just a place to put your files online, accessible from anywhere, where you define who can see/take/modify them (or, y’know, accidentally leak them if you’re not careful).
What I almost never see people mention is just how wild it is that S3 doesn’t care what “kind” of item you put in there. LOL, there’s no “I’m an image folder” or “I only keep docs” nonsense. Shoot, dump your entire project’s backups AND your cat pictures in there, as long as you name ’em right. And no, you don’t have to organize this stuff in “folders” (the AWS console PRETENDS you can, but under the hood, EVERY SINGLE THING is just a big flat list of objects with slashes in their names).
How do people use ‘em? CDN storage (fancy way for websites to serve images/videos), disaster backup, logs, static websites, you name it. If you’re setting up a new project and think “wait—do I shove ALL my stuff in here???” the answer’s basically “yes, but only what you need to keep long-term, share, or want crazy amounts of redundancy for.” If you just need a place to store temporary files for super fast access (like for computation), other AWS services might make more sense.
Quick rant: everybody goes “S3 is cheap!” but when you get nickeled and dimed for PUT, GET, and transfer operations, suddenly you’re weeping over a surprise bill. So, watch for that.
Anyway, to start—find the S3 service in the AWS console, click “Create bucket,” give it a name, set your region, and choose who can see the loot inside. If you’re nervous, keep everything private and just grant access specifically to your project/app. Don’t overthink the “folder” structure—it’s all smoke and mirrors.
TL;DR: S3 bucket is an infinite cloud backpack. Store digital junk—or treasures—safely, but don’t leave it wide open unless you want random internet people poking around. And trust me, don’t ignore the costs.
If you’re still lost after reading explanations from @mikeappsreviewer’s attic analogy and @byteguru’s bottomless tote bag comparison, let me throw something else at you. Imagine the giant claw machine at a crappy arcade, except you always get your digital toy (file) out, whether it’s a cat meme, giant ZIP, or the sassy error log that ruined your day.
S3 buckets aren’t folders (not really, despite what the dumb interface shows). They’re ginormous bins where every file/object you add is tracked by a unique name. Use slashes and it pretends you have folders. You’re just tricking your own brain—not AWS.
It’s like that: dump in whatever, however, whenever, as long as you obey a few rules. Permissions? Be careful—a public bucket means anyone can ransack your stuff. Default is private; stay that way unless you’re sure you want the public to see it (think web assets, not your draft breakup letter).
Also, don’t let anyone tell you it’s cheap. Storage looks cheap upfront, then you get hit on uploads, downloads, and “API requests.” It piles up. I got stung early on and now I literally set budget alerts before I dump anything bigger than a cat gif.
But yeah, new project? Create a bucket, make it private, upload a test file, play with permissions, and BREATHE. It’s less magic than hype. Start simple—figure out what your project needs and scale from there. Just don’t go deleting buckets willy-nilly, or you’ll be crying with no backup in sight.
Alright, I’ll cut through the fancy metaphors (virtual attics and digital suitcases, I’m looking at you!) and drop a minimal take: an Amazon S3 bucket is basically a big bin for your data—files, images, backups, logs, whatever—living on AWS. You put “objects” (files + metadata) into buckets, set some rules (who can see/move/change stuff, auto-delete old files, etc.), and AWS handles the reliability, redundancy, and scale automatically. You don’t worry about hard drives, CPUs, or network cables.
Why is S3 so useful?
- Insanely scalable: toss in gigabytes or petabytes, doesn’t matter.
- Ridiculously reliable: AWS stores copies in multiple places.
- Fine-grain controls: lock buckets down or make them public for hosting static sites/CDN.
- Integrates with tons of AWS products and third-party tools.
Cons:
- Pricing confusion: Reading the bill can be trickier than actually using S3.
- Privacy pitfalls: Public bucket misconfigurations = juicy headlines.
- Not for everything: Not a normal filesystem, so running databases directly in S3 is a no-go.
Competitors? You’ve got great breakdowns from byteguru and mikeappsreviewer above, but in the real world, alternatives include Google Cloud Storage and Azure Blob Storage—they all do “buckets,” just with different flavors and ecosystem lock-in.
Bottom line—if your app, site, or project needs flexible and secure storage you’ll access via the internet (API, SDK, or web console), S3 buckets are the AWS-approved tool for the job.